BCR Portable Performance
The very design of CDS (and BCR, a specific dialect and implementation
of it) squeezes every ounce of bandwidth from a system, so many programs
will communicate much more efficiently than if written using interfaces
like MPI or PVM. There are three basic reasons for this:
-
Communication within MPI and PVM is based on moving the data from a user-specified
buffer in the sender to a user-specified buffer in the receiver, even
if the sender and receiver are on the same processor or share access to
common memory. In CDS, the user can often allow CDS to dictate
where the buffer involved in the communication is stored, so in some cases
it can put it into memory accessible to both the sender and the receiver,
thereby completely avoiding copying (e.g. by using the same buffer for
both the sender and the receiver) and reducing both overall latency and
the consumption of memory bandwidth.
-
Communication within MPI and PVM often utilizes hidden "control" or "housekeeping"
messages to ensure that there is sufficient buffer space on the receiver,
etc., and these messages and their protocols eat up bandwidth and latency
in the network. In CDS, there is aways a user-accessible buffer
waiting at the receiving end of any communication, so these messages can
often be avoided. The network latency and bandwidth (aside from a
tiny amount used by CDS-specific message headers) is delivered directly
to the user application.
-
Communication within MPI and PVM includes processing of the data through
a "type", adding to the latency (or "overhead") of communication.
In CDS, the user application can access the raw bytes being transferred,
and when dealing in a homogeneous environment, this is often all that is
required. The overhead of processing the type can thereby often be
omitted completely, and in some other cases performed concurrently with
other communication.
These are illustrated by the very simple "ring" program which is provided
as part of the BCR "test" directory. It just passes data regions
(MPI and PVM would call them "messages") of different sizes (10 bytes,
100 bytes, 1000 bytes, and 10000 bytes) around a ring of CCEs (effectively
"processes"). It starts by reading a file that tells it how many
CCEs (i.e. processes) to put on each processor, then starts those CCEs,
and every CCE then performs a very simple loop consisting of alternating
puts
and a gets to neighboring CCEs.
The platform for this test consisted of two off-the-shelf computers
connected with a 10BaseT ethernet hub. One computer is a 2-processor
Pentium III SMP PC, running at 850MHz/processor, the other is a Mac Powerbook
G3 ("Wallstreet"), running at 266 MHz.
The program was run with four different configurations:
-
2 CCEs ("processes"), both on the 2-processor SMP PC
-
2 CCEs, one on the PC and one on the Mac.
-
3 CCEs, all on the 2-processor SMP PC.
-
3 CCEs, two on the SMP PC and one on the Mac.
Here is a graph of the "Effective Bandwidth" result obtained by averaging
3 runs in each configuration, with each result calculated as the region
size (in Bytes/region) times the number of regions passes (in regions)
divided by the elapsed time (in seconds) to yield bandwidth (Bytes/sec).
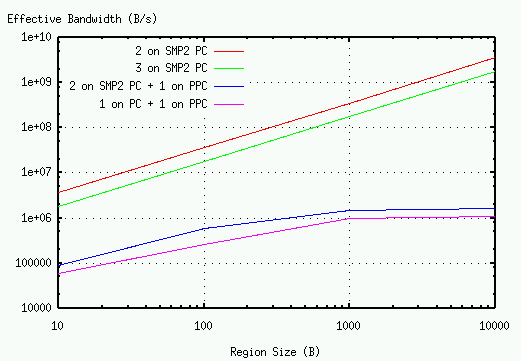 Note that the red and green lines at the top are linear without bound,
parallel, and very steep. This is because, on an SMP (or single processor),
the time to "pass" a region is a constant (i.e. the time to pass a pointer),
and completely independent of the region size. For the red line,
this fixed latency is about 2.8 microsecs, and for the green line it is
about twice that (because two of the three CCEs are effectively competing
for one of the two processors at all times). The (non-logarithmic)
slope of those lines are equal to the inverses of those times, since bandwidth
(y) equals bytes (x) divided by this time. As a result, for regions
of 10000 bytes, the effective bandwidths on this platform are enormously
high, 1.8 GB/sec and 3.7 GB/sec, and would be even higher for larger regions
or faster platforms. You will not see performance like that from
PVM or MPI in any configuration, even working through shared memory, because
they must move data to communicate.
Note that the red and green lines at the top are linear without bound,
parallel, and very steep. This is because, on an SMP (or single processor),
the time to "pass" a region is a constant (i.e. the time to pass a pointer),
and completely independent of the region size. For the red line,
this fixed latency is about 2.8 microsecs, and for the green line it is
about twice that (because two of the three CCEs are effectively competing
for one of the two processors at all times). The (non-logarithmic)
slope of those lines are equal to the inverses of those times, since bandwidth
(y) equals bytes (x) divided by this time. As a result, for regions
of 10000 bytes, the effective bandwidths on this platform are enormously
high, 1.8 GB/sec and 3.7 GB/sec, and would be even higher for larger regions
or faster platforms. You will not see performance like that from
PVM or MPI in any configuration, even working through shared memory, because
they must move data to communicate.
The magenta line at the bottom represents simple transfer over the ethernet.
BCR internally utlizes UDP/IP communications, and dynamically tunes network
parameters (such as time-outs, window-size, and acks) to conform to current
network and application needs. In this case, it delivers almost the
entire bandwidth of the 10BaseT ethernet to the application, with region
sizes of just 1000 bytes each. This is superior to PVM and MPI in
similar circumstances (e.g. see links below). The blue line is a
hybrid configuration, communicating through shared memory (by just passing
pointers) when possible, and communicating over the ethernet when necessary,
all completely invisible to the program. (Note that, in this case,
one traversal of the ring consists of two traversals of the ethernet plus
one through fixed-latency shared memory.) Use of a such a hybrid
approach using other programming methodologies (e.g. MPI + OpenMP) would
require significant integration of underlying software tools and extreme
exposure of complexity to the programmer.
"Ring" is a very simple program, and may not be a good predictor of
the performance you will see when using BCR. For example, no conversion
or translation is performed in this program while passing regions around
the ring, but in general, BCR allows those operations to be used sparingly,
especially when working among homogeneous processors like those in an SMP.
Some similar (though not identical) statistics for MPI and PVM can be
found at http://www.hpcf.upr.edu/~humberto/documents/mpi-vs-pvm/.
Please be aware of potentially different metrics (e.g. Mbits/sec vs. MBytes/sec)
when comparing. (Please let us know
of links to other pertinent performance comparisons.)
Copyright 2002 © elepar All rights reserved
Back to BCR (CDS Product page)